
 |
| Ah, the wonders of Windows Phone 8.0 ... Failing eyesight, Frustration and Squirrel chasing |
Currently, there is not much freely available documentation on how Windows Phone 8.0 stores data so it is hoped that the information provided in this post can be used as a stepping stone for further research / possible scripting. Hopefully, analysts will also be able to use this post to help validate any future tool results.
Special Thanks to Detective Cindy Murphy (@CindyMurph), Lieutenant Jennifer Krueger Favour (@rednogn) and the Madison Police Department ("Forensicate Like A Champion!") for providing the opportunity and encouragement for this research.
Unfortunately, due to time contraints and a limited test data set, I wasn't able to write an all-singing/all-dancing script. Instead, some one-off scripts were created to extract/sort the relevant data a lot quicker than it would have taken to do manually. Rather than releasing scripts that are customized for a limited set of test data (which I don't have easy access to any more) - this post will be limited to documenting the data sources/structures.
OK, so no free tool and you're still here reading huh? In Yoda voice: "The nerd runs strong in this one" ;)
Thanks to Maggie Gaffney from Massachusetts State Patrol / Teel Technologies, the initial test data (.bin file) was sourced via JTAG from a Nokia 520 Windows 8.0 phone - a "cheap" smart phone common to prepaid plans. The .bin file was then opened in X-Ways Forensics to parse the 28(!) file system partitions and to export out files of interest. The exported files were then viewed in hex view using Cellebrite Physical Analyzer (love the data interpretation and colour coded bookmarking!). Later, we were also able to get our paws on some test data from a HTC PM23300 Windows Phone 8.0 phone courtesy of JoAnn Gibb from the Ohio Attorney Generals Office. UPDATE: Thanks also to Brian McGarry (Garda) for his testing feedback and help with the SMS and Call Logs. It's awesome knowing people that know people!
Note: The Nokia 520 does not display the full SMS timestamp info (threaded messages display date only).
So while we can potentially re-create the order of threaded messages as per the test phone, we can't easily validate the exact time an SMS message was sent/received. There's a good chance that other Windows Phone 8.0 phones will use the same timestamp mechanism and hopefully they will display the full timestamp.
So where's the data?!
The SMS content, MMS file attachment info and Contacts information are stored (via the 28th Partition) in:\Users\WPCOMMSSERVICES\APPDATA\Local\Unistore\store.vol
Various .dat files containing MMS content are also stored in sub-directories of:
\SharedData\Comms\Unistore\data
The Call log is stored in:
\Users\WPCOMMSSERVICES\APPDATA\Local\UserData\Phone
The "store.vol" and "Phone" files seem to be ESE Databases (see explanantions here and here) with the magic number of "xEF xCD xAB x89" present at bytes 4-8. Consequently, we tried opening "store.vol" using Nirsoft's ESE Database viewer but had limited success - the SMS message texts were not viewable however other data was. This suggests that maybe the "store.vol" file differs in some way from the ESE specification and/or the tool had issues reading the file.
Joachim Metz has also both documented (here and here) and written a C library "libesedb" to extract ESE databases. Unfortunately, I didn't discover Joachim's library until after we started poking around .. Anyway, it was a pretty
Viewing "store.vol" using Cellebrite Physical Analyzer, relevant data was observed for text strings (eg phone numbers, SMS text strings) encoded in UTF-16 LE throughout the file.
As a database file there will be tables. Each table will have columns of values (eg time, text content, flags). A single (table row) record will thus have data stored for each column.
Table data will be organized within the file somehow (eg multiple SMS records organized into page blocks). So it is likely that finding a hit for a specific SMS will lead you to the contents of other SMS messages (potentially around the same timeframe).
The Nokia 520 was actually locked with a 4 digit PIN when we started investigating. Without access to the phone, any manual inspection/validation would have been impossible. It was unknown if the phone would have been wiped if too many incorrect PINs were entered. So any guesses would have to be documented and carefully chosen. It wasn't looking good ... until a combination of thinking outside the box and a touch of luck lead us to an SMS text message (in "store.vol") with the required 4 digit code. Open sesame!
Some things we tried with the data ...
To find specific SMS records we searched for unique/known strings from the SMS text (eg "Look! A Squirrel!"). A single record was found per SMS in "store.vol" and each record also contained a UTF-16-LE string set to "SMStext".To find contact information, we searched for known phone number strings (eg +16085551234, 123456, 1234). Some numbers were observed in "store.vol" in close proximity to "SMStext" strings while other instances were located close to what appeared to be contact information (eg contact names).
To search for field markers and flags, we compared separate SMS text records and looked for patterns/commonalities in the hex. Sometimes the pattern was obvious (eg "SMStext" occurs in each SMS message) and sometimes it wasn't so obvious (sometimes there is no discernible pattern!).
Figuring out the timestamp format being used was HUGE. Without it, we could not have figured out the order messages were sent/received. Using Cellebrite Physical Analyzer to view the "store.vol" hex, Eagle-eyed Cindy noticed that there were 8 byte groupings occurring before/after the SMS text content. These 8 bytes were usually around the same value range (eg in LE xFF03D2315FE1C701). Which is what you'd expect within a single message. Subsequent messages usually had larger values - which corresponds to messages sent/received at a later time.
Like most hex viewers, Cellebrite Physical Analyzer can interpret a predefined number of bytes from the current cursor position and print a human friendly version. Using this, Calculon Cindy showed an otherwise oblivious monkey that these 8 byte groupings could be interpreted as MS FILETIME timestamps! To be honest, I was expecting smaller 4 byte timestamps - Silly monkey!
By comparing the 8 byte values surrounding a specific SMS text message (eg "Look! A Squirrel!") with the date displayed on the phone for that message, we theorized that our mysterious timestamps were *probably* MS FILETIME timestamps (No. of 100 ns increments since 1 January 1601 in UTC). For example, xFF03D2315FE1C701 = Sat, 18 August 2007 06:15:37 UTC. As the phone did not display the exact time for each SMS, we could only use the order of threaded messages and the date displayed to somewhat confirm our theory. Various SMS sent/received dates on the phone were spot checked against a corresponding "store.vol" entry timestamp date and the date values consistently matched.
UPDATE: FTK 5.4 can also be used to view the database tables in the store.vol and Phone files. Thanks to JoAnn for the tip!
OSForensics also has an ESE database viewer which can be used to view the phone's databases. As an added bonus, it also has a Windows Registry viewer for inspecting the phone's hives. Thanks to Brian for the suggestion!
What the data looks like
After some hex ray vision induced cross-eyedness (who knew that looking at hex is almost like a curse!), we think we've figured out some general data structures for SMS, MMS, Contacts and Call log records. There's still some unknowns/grey areas but it's a start.- On the data structure diagrams below, "?" is used to denote varying/unknown number of bytes.
- FILETIMEs are LE 8 byte integers representing the number of 100 ns intervals since 1 JAN 1601.
- In general, strings are null terminated and UTF-16-LE encoded (ie 2 bytes per character).
Sent / Received SMS records
There are two types of SMS data structures which are mixed together. Each type of SMS structure contains a UTF-16-LE encoded string for "IPM.SMStext". However, one type contains phone number strings and the other does not.For later ease of understanding, we'll say these "SMStext" records occur in "Area 1". UPDATE: Area 1 corresponds to the "Message" table.
Initially, monkey was confused about why some SMS records had phone numbers and some didn't. However, by inspecting the unlocked phone, we were able to confirm that the SMS message records with no number corresponded to sent SMS.
 |
| Sent "SMStext" record (from Area 1 in "store.vol") |
Note 1: Note the lack of Phone number information. From test data, FILETIME values (in red and pink) seemed a little inconsistent. Sometimes FILETIMEs within the same record matched each other and other times they varied by seconds/minutes.
Note 2: The Sent Text string (in yellow) is null terminated and encoded in UTF-16-LE.
 |
| Received "SMStext" record (from Area 1 in "store.vol") |
Note 1: Received SMS have multiple source phone number strings listed (in orange). These seem to remain constant within a given record (eg PHONE0 = PHONE1 = PHONE2 = PHONE3)
Note 2: Similar to Sent "SMStext" records, the FILETIMEs (in red and pink) within a record might/might not vary.
Note 3: The Received Text string (in yellow) is null terminated and encoded in UTF-16-LE.
To find out the destination phone number for a sent SMS we can make use of the factoid observed by searching "store.vol" for the FILETIMEs from a specific Sent "SMStext" record.
It appears that FILETIMEs 1, 3 & 4 (in pink) from a given Sent "SMStext" record usually occur once in the entire "store.vol". The FILETIME2 value (in red) however, also appears in a second area ("Area 2"). UPDATE: Area 2 corresponds to the "Recipient" table. This area has a bunch of different looking data records each containing the null terminated UTF-16-LE encoded string for "SMS". Also contained in each data record is a phone number string. The "Area 2" SMS records look like:
 |
| "SMS" record (from Area 2 in "store.vol") |
Note 1: Each "SMS" record contains a UTF-16-LE encoded string for "SMS".
Note 2: From both sets of test data, there seems to be a consistent number of bytes between:
- The FILETIMEX (in red) and "SMS" string (in kermit green) and
- The "SMS" string (in kermit green) and the Phone number string (in orange).
So, each sent "SMStext" FILETIME2 value (from Area 1) should have a corresponding match with an "SMS" record's FILETIMEX value (in Area 2). In this way, we can match a sent "SMStext" message with the destination phone number via the FILETIME2 value. Sounds a little crazy right? But the test data seems to confirm this. Purrr!
Contacts
Contact information is also located in "store.vol". UPDATE: This area corresponds to the "Contact" table. There were 2 main observed data structure types - both contained phone number and name information however, one data type had an extra 19 digit number string. It was later discovered via phone inspection that the records with the extra digit strings corresponded with "Hotmail" address book entries. It would be interesting to see if the 19 digit number corresponded to a unique hotmail user ID of some kind.The second type of contacts structure was a "Phonebook" entry - presumably these contact types were entered into the phone by the user rather than slurped up from a Hotmail account.
Common to both contact records were multiple occurrences of the same contact name and phone number. OCD phonebook, OCD phonebook, OCD phone book ... ;)
 |
| "Hotmail" Contacts record (from "store.vol") |
 |
| "Phonebook" Contacts record (from "store.vol") |
Note 1: The flag value (in red) which can be used to determine if the contact record is a "Hotmail" or "Phonebook" entry.
Note 2: The potential 6 byte magic number (0xFFFFFF2A2A00) for Contact records should make it easier to find each entry. This was discovered by Sharp-eyed Cindy on the last day (by which time monkey had lost the will to live).
Note 3: There is also an "End Marker" which has the following value in hex: [01 04 00 00 00 82 00 E0 00 74 C5 B7 10 1A 82 E0 08]. This value lead to a couple of extra contact records which did not have the 6 byte magic number at the beginning.
Note 4: The 19 digit string (in pink) could be a potential Hotmail ID.
UPDATE: Since this was originally written, new Contact test data has been observed. These have slightly different record structures but all records seem to have the same "End Marker" and the last 3 Unicode string fields. The last and 3rd last strings can thus be extracted for name/phone (and possibly email) information.
MMS data
Further research is required for MMS records (eg linking timestamps and phone numbers to sent files). But here's what we've learned so far ...Various .dat files containing MMS content (eg there was a .dat file containing a sent JPEG and another .dat file containing the accompanying text) are stored in:
\SharedData\Comms\Unistore\data
under 3 sub-directories: "0", "2" and "7". These folders might correspond to Sent, Received and Draft???
There were multiple .dat files with similar names each seemingly containing info for different parts of the same MMS.
In "store.vol", there are records containing the UTF-16-LE encoded string for "MMS". These records also contain 3 filename strings and a filetype string (possibly the MIME type eg "image/jpeg"). From my jet-lagged memory, I want to say that the filename strings were pointing to the same filename and there were multiple "MMS" entries for a single MMS message (ie each MMS message has three separate files associated with it). But you should probably should check it out for yourself ...
UPDATE: These MMS records correspond to the "Attachment" table.
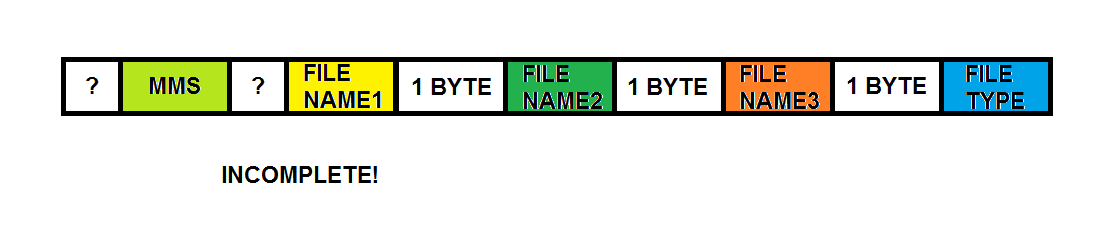 |
| MMS record (from "store.vol") |
Call log
The Call log information is located in the "Phone" file. Each Call log record contains a flag (in blue) to mark whether a call record is Missed / Incoming / Outgoing. The flag values were confirmed via inspection of the phone and corresponding Call log record. There's also Start and Stop FILETIMEs, repeated contact names and repeated phone numbers.Of potential interest is a 10 digit ASCII encoded string (in grey) and what looks to be a GUID (in light purple). Each call record had the same GUID string value enclosed by "{}".
UPDATE: The GUID appears to be consistent between 3 phones (2 x Nokia Lumia 520 and HTC PM23300). The ASCII ID string has also been observed to be greater/less than 10 digits.
 |
| Revised Call log diag (from "Phone") |
Summary
So there you have it - we started off knowing very little about Windows Phone 8.0 data storage and now we know a considerable amount more especially regarding SMS records.Due to time constraints, it was not possible to investigate the non-SMS related data areas (ie MMS, Call log, Contacts) with the same level of detail. However, it's probably better to share what we've discovered now as I don't know when I'll be able to perform further research.
The observations in this post may not be consistent for Windows 8.1 and/or on other models of Windows phones but hopefully this post can still serve as a starting point. As always, check that the underlying data matches your expectations!
It was really awesome having someone else to bounce ideas off when hex-diving. I'm pretty sure I would have missed some important details (eg the FILETIME timestamp) had it not been for another set of eyes. Of course, that's not always going to be possible so I also appreciated the other opportunities to work automonously / with minimal supervision. Someday monkey might have to do this on his lonesome! :o
Initially, it was easy to tie my idea of success with the "I have to code a solution for every scenario/data set". It would have been awesome if I could have done that but the fact was - we didn't have any SMS messages from "store.vol" at the start and after running the one-off SMS script, we had 5000+ messages sorted in chronological order with their associated phone numbers. Success doesn't have to be black and white. It sounds cliche but focusing on little wins each day made it easier to start eating the metaphorical elephant. Now please excuse me, while I adjust my pants ...
UPDATED 22OCT2015 - Deleted record test observations from a Nokia Lumia 530 running Windows Phone 8.10
Upon deletion, the original SMS and Contact records (in Data:\USERS\WPCOMMSSERVICES\APPDATA\Local\Unistore\store.vol) and Call log records (in Data:\USERS\WPCOMMSSERVICES\APPDATA\Local\Userdata\Phone) are OVERWRITTEN with 0x44 values (ASCII "D"). The same ESE database behaviour is suspected to occur with MMS records in store.vol - however due network issues, this has not been verified.
However, under certain conditions, it may still be possible to recover this deleted ESE record data (eg SMS, Contacts, Call log, *MMS not tested) from a Nokia Lumia 530 running Windows Phone 8.10 because duplicate records of the deleted data can potentially be recovered from:
- ESE .log files (eg Data:\USERS\WPCOMMSSERVICES\APPDATA\Local\Userdata\UDM.log and Data:\USERS\WPCOMMSSERVICES\APPDATA\Local\Unistore\USS.log)
- Data:\pagefile.sys
Prior experience with a Nokia Lumia 520 Windows Phone 8.0 device showed that SMS data may also be contained in USStmp.log (in the same directory as the USS.log). See Det. Cindy Murphy's SANS whitepaper for further details.
Also see here for more details on ESE .log files (eg naming conventions).
It is suspected that the more the device is used before imaging, the less likely deleted data will be recoverable.
For example, general phone usage will result in pagefile.sys getting updated and ESE database modifications (eg new records) can potentially change the .log files.
This makes it difficult to state how long deleted records will be recoverable (possibly hours rather than days/weeks?).